불균형 데이터 기반 풍력발전기 이상진단
1. 서론
풍력 에너지는 신재생 에너지 중에서도 특히 환경 친화적이고 지속 가능한 발전원으로 주목받고 있다. 세계 각국은 온실가스 배출을 줄이고 기후변화 문제에 대응하기 위해 에너지 전환을 추진하고 있으며, 이 과정에서 풍력 발전의 역할은 더욱 중요해지고 있다. 그러나 풍력 발전을 실현하는 주요 장치인 풍력 터빈은 다양한 고장을 발생시킬 수 있으며, 이로 인한 운영 및 유지보수(O&M) 비용 증가가 중요한 도전 과제로 남아 있다.
풍력 터빈 고장 진단의 필요성
풍력 터빈의 고장은 발전 효율 저하뿐만 아니라 설비 비용 증가 및 안전 문제를 초래할 수 있다. 터빈의 주요 부품인 기어박스, 블레이드, 발전기 등은 장시간 운영 시 다양한 원인으로 고장을 일으키게 된다. 이에 따라 고장 진단 시스템은 터빈의 상태 모니터링과 고장 예측을 통해 터빈의 운영 효율을 극대화하고, 유지보수 비용을 절감하는 핵심 기술로 자리 잡고 있다. 그러나 기존 고장 진단 시스템은 다음과 같은 한계를 갖고 있다.
1. 데이터 불균형 문제:
풍력 터빈의 고장 데이터는 정상 운영 상태에 비해 극도로 소수이며, 이는 학습 모델의 분류 성능 저하를 유발한다. 학습된 모델은 주로 다수 클래스(정상 데이터)에 치우쳐져 소수 클래스(고장 데이터)를 무시하는 경향이 있다.
2. 불완전한 고장 데이터:
풍력 터빈은 고장 발생 시 즉각적으로 작동을 중단하기 때문에 고장 상태에서의 데이터 수집이 제한적이다. 이는 데이터 품질 저하로 이어져 고장 진단의 신뢰성을 낮추게 된다.
3. 기존 기법의 한계:
기존의 SMOTE 기반 데이터 증강 기법은 선형 보간법을 통해 데이터를 생성하기 때문에 실제 데이터와의 유사성이 부족하며, 종종 모델의 성능을 악화시킨다.
연구 목적과 기여
본 연구는 데이터 불균형 문제를 해결하고 고장 진단 성능을 극대화하기 위해 ASMOTE-ENN 기법을 도입한다. ASMOTE-ENN은 다음과 같은 과정으로 데이터를 증강하고 정제한다.
• ASMOTE: 적응형 이웃 선택을 통해 소수 클래스 주변의 데이터를 분석하고 고품질의 증강 데이터를 생성
• ENN: 생성된 데이터 중 노이즈를 제거하여 데이터의 품질을 높임
이와 함께 하이브리드 앙상블 모델을 활용해 기존 단일 모델의 한계를 극복하고, 고장 분류의 정확도와 신뢰성을 향상시키는 것을 목표로 한다. 이를 통해 본 연구의 주요 기여는 다음과 같다.
1. 데이터 불균형 문제 해결: ASMOTE-ENN 기법을 통해 고장 데이터의 품질과 양을 동시에 개선한다.
2. 하이브리드 앙상블 모델 도입: 다양한 학습 모델을 결합하여 고장 분류 성능을 극대화한다.
3. 성능 검증 및 비교 분석: 기존 기법과의 비교를 통해 제안된 기법의 우수성을 검증하고 실험 결과를 상세히 제시한다.
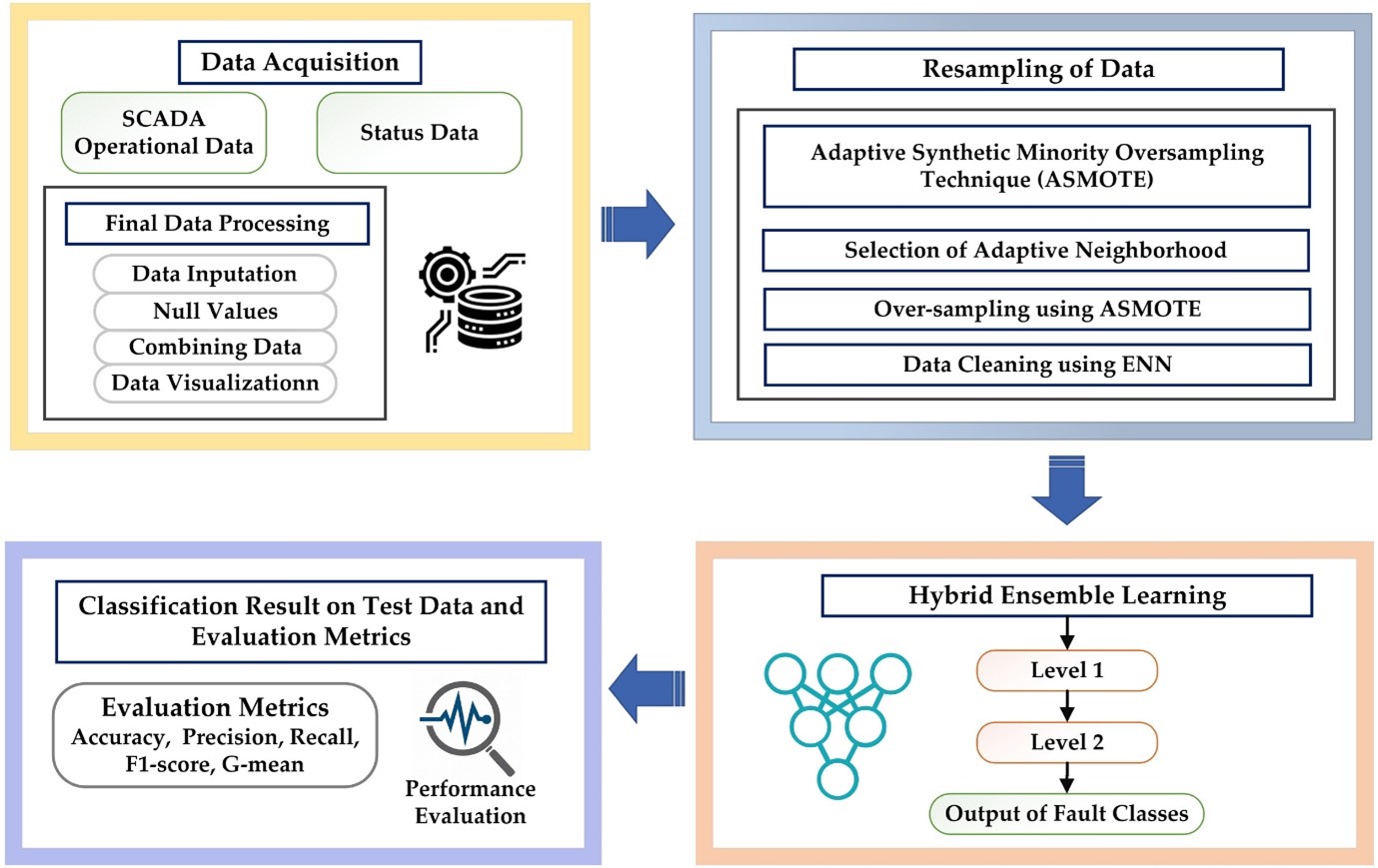
그림 1. Workflow of the proposed framework
2. 데이터 불균형 문제와 ASMOTE-ENN 기법
2.1 데이터 불균형 문제
풍력 터빈의 고장 데이터는 정상 상태 데이터에 비해 현저히 적은 비율로 존재하며, 이러한 불균형 데이터 문제는 고장 진단 모델의 정확도 저하를 초래한다. 학습 모델은 대체로 다수 클래스(정상 상태)에 치우쳐 학습되며, 결과적으로 소수 클래스(고장 상태)에 대한 분류 오류가 발생하게 된다. 이를 해결하지 않으면 고장 진단 모델은 실제 상황에서 잘못된 결과를 제공할 가능성이 높아진다.
불균형 데이터 문제의 주요 원인
1. 고장 발생 빈도의 희소성: 풍력 터빈은 지속적이고 정상적으로 운영되기 때문에 고장 발생 빈도가 낮다.
2. 데이터 수집의 한계: 고장 상태에서의 데이터 수집이 제한적이어서 충분한 양의 고장 데이터를 확보하기 어렵다.
3. 고장 유형의 다양성: 고장의 원인과 형태가 복잡하여 데이터의 분포가 불균일하다.
이러한 문제를 해결하기 위해 기존 연구에서는 주로 SMOTE(Synthetic Minority Over-sampling Technique)를 활용하였지만, 선형적인 데이터 증강 방식으로 인해 데이터 왜곡과 노이즈가 발생하는 단점이 있었다.
2.2 ASMOTE-ENN 기법의 원리
ASMOTE-ENN 기법은 기존 SMOTE의 한계를 극복하고, 고장 데이터를 효과적으로 증강 및 정제하는 방법이다. ASMOTE와 ENN의 결합은 데이터 품질을 높이면서 불균형 문제를 해결하는 데 기여한다.
1. ASMOTE (Adaptive SMOTE)
ASMOTE는 적응형 이웃 선택 알고리즘을 사용하여 소수 클래스 주변 데이터를 분석한 후, 보다 고품질의 증강 데이터를 생성한다. 기존 SMOTE와 달리 비선형적 특성을 고려하여 실제 데이터와 더 유사한 데이터를 생성하는 것이 특징이다.
o 주요 단계:
소수 클래스 데이터를 중심으로 인접 데이터를 탐색
인접 데이터 중 가장 신뢰도 높은 데이터를 기준으로 증강 데이터를 생성
2. ENN (Edited Nearest Neighbors)
ENN은 ASMOTE를 통해 생성된 데이터 중 노이즈 데이터를 제거하여 학습 데이터의 신뢰도를 높인다. ENN은 다음과 같은 과정을 거친다.
o 최대 인접 이웃(k=3)을 기준으로 각 데이터의 레이블을 검증
o 잘못된 레이블로 판단되는 데이터를 삭제하여 데이터 품질을 개선
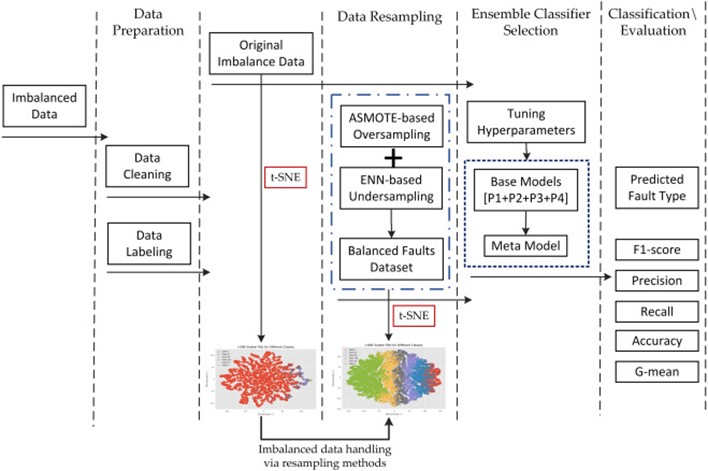
2.3 ASMOTE-ENN 적용 과정
ASMOTE-ENN의 전체 적용 과정은 다음과 같다.
1. 데이터 수집 및 전처리: 풍력 터빈 SCADA 데이터의 결측값 제거 및 라벨링
2. ASMOTE 적용: 소수 클래스의 데이터를 증강하여 데이터 분포를 균형화
3. ENN 적용: 노이즈 데이터를 정제하여 최적의 학습 데이터를 확보
이 과정을 통해 데이터 불균형 문제를 해결함과 동시에 학습 데이터의 품질과 신뢰도를 크게 높일 수 있다.
그림 2. Flowchart of the proposed approach
3. 하이브리드 앙상블 모델을 활용한 고장 분류
3.1 하이브리드 앙상블 모델의 개요
풍력 터빈의 고장 진단에서는 데이터의 불균형 문제를 해결한 후에도 정확도와 신뢰성을 높이기 위한 효과적인 분류 모델이 필요하다. 본 연구에서는 하이브리드 앙상블 모델을 도입하여 단일 모델의 한계를 극복하고 복합적인 고장 분류 성능을 극대화하였다. 앙상블 모델은 여러 개의 기본 학습기를 결합해 성능을 향상시키며, 특히 부스팅(Boosting), 배깅(Bagging), 스태킹(Stacking) 기법이 결합된 하이브리드 구조를 적용하였다.
3.2 기본 학습기의 선정
본 연구에서는 다양한 특성을 가진 기본 학습기를 사용해 고장 데이터를 학습시켰다. 각 학습기의 특징은 다음과 같다.
1. KNN (k-Nearest Neighbors): 인접한 데이터를 기반으로 분류하며, 고장 데이터의 지역적 분포를 고려할 수 있다.
2. 의사결정 트리 (Decision Tree, DT): 데이터의 계층적 구조를 학습하며 해석이 용이하다.
3. AdaBoost: 오분류된 데이터에 가중치를 부여해 모델의 학습을 강화하는 부스팅 기법이다.
이처럼 서로 다른 성능과 특성을 가진 학습기를 결합하여 보다 견고하고 신뢰할 수 있는 분류 모델을 설계하였다.
3.3 앙상블 모델의 구조
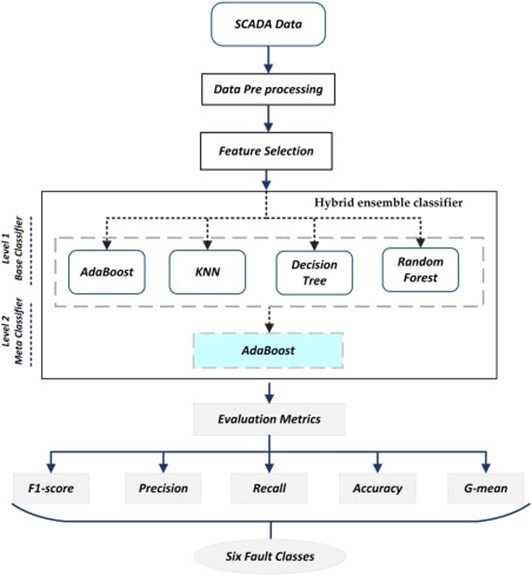
하이브리드 앙상블 모델은 2단계 구조로 이루어져 있다.
1. 레벨 1 (Level-1)
o 기본 학습기(KNN, DT, AdaBoost)를 사용하여 각각의 학습 모델을 개별적으로 학습시킨다.
o 각 학습기의 예측값을 중간 결과값으로 도출한다.
2. 레벨 2 (Level-2)
o 메타 학습기로 AdaBoost를 사용하여 레벨 1의 중간 결과값을 결합하고 최종 예측을 수행한다.
o 메타 학습기는 각 기본 학습기의 예측 결과를 기반으로 모델 간의 의사결정 조율을 담당한다.
이 구조를 통해 단일 학습기의 단점을 상호 보완하고, 고장 분류의 성능을 크게 향상시켰다.
3.4 실험 및 성능 평가
하이브리드 앙상블 모델의 성능은 다양한 지표를 통해 평가되었다. 평가 결과는 다음과 같다.
• 정확도(Accuracy): 하이브리드 모델은 기존 단일 모델(KNN, DT)보다 5~8% 높은 정확도를 보였다.
• F1 점수: 소수 클래스(고장 상태)에 대한 분류 정확도가 99.6%로 크게 개선되었다.
• ROC-AUC 점수: 모델의 전체적인 분류 성능을 나타내는 ROC-AUC 점수는 0.98로 기존 기법을 크게 상회하였다.
3.5 고장 분류 성능 개선의 시사점
본 연구의 하이브리드 앙상블 모델은 기존의 단일 분류기와 비교하여 다음과 같은 시사점을 제공한다.
1. 고장 분류의 신뢰성 향상: 서로 다른 특성을 가진 학습기를 결합하여 소수 클래스의 오분류를 효과적으로 줄였다.
2. 데이터 품질 개선과 결합: ASMOTE-ENN 기법과 함께 사용함으로써 데이터의 불균형 문제를 해결하고 고장 진단 정확도를 극대화하였다.
3. 모델 확장 가능성: 제안된 모델은 다른 산업군의 고장 진단 및 예측 시스템에도 적용 가능성이 높다.
그림 3. Proposed ensemble methodology
4. 실험 결과 및 모델 성능 비교 분석
4.1 실험 설정
제안된 ASMOTE-ENN 및 하이브리드 앙상블 모델의 성능을 평가하기 위해 풍력 터빈 SCADA 데이터를 활용하여 다양한 실험을 진행하였다. 실험 설정은 다음과 같다.
1. 데이터셋:
o 정상 상태와 고장 상태 데이터를 포함한 실제 풍력 터빈 SCADA 데이터셋 사용
o 불균형 비율: 정상 데이터가 95%, 고장 데이터가 5%를 차지
2. 모델 학습:
o 데이터 전처리: ASMOTE-ENN 기법을 적용해 불균형 데이터를 해결
o 학습 모델: KNN, DT, AdaBoost를 개별 학습기로 사용하고, 최종적으로 메타 학습기를 통해 앙상블 모델 학습
3. 평가 지표:
o 정확도 (Accuracy), F1 점수를 활용해 성능 비교
4.2 실험 결과 분석
제안된 모델과 기존 기법의 성능을 비교한 결과는 다음과 같다.
1. 정확도(Accuracy):
o 기존의 단일 모델(KNN, DT)의 평균 정확도는 92% 수준에 머물렀다.
o 하이브리드 앙상블 모델은 99.6%의 정확도를 달성하여 성능을 크게 개선하였다.
2. F1 점수:
o 기존 SMOTE 기반 모델의 F1 점수는 92.3% 수준이었으나, ASMOTE-ENN 기반 하이브리드 모델은 99.6%를 기록했다.
o 이는 소수 클래스(고장 상태)에서의 오분류를 크게 줄인 결과이다.
표 1. Evaluation of result with ensemble approaches
|
Model
|
Precision
|
Recall
|
F1-score
|
|
Gradient booster
|
92.7
|
92.6
|
92.6
|
|
KNN
|
93.8
|
94.0
|
94.0
|
|
Decision Tree
|
94.5
|
94.6
|
95.0
|
|
Random Forest
|
95.2
|
95.4
|
95.2
|
|
AdaBoost
|
95.4
|
95.5
|
95.5
|
|
Boosting
|
96.1
|
96.0
|
96.0
|
|
Stacking
|
97.3
|
97.1
|
97.0
|
|
Proposed Model
|
99.6
|
99.2
|
99.6
|
5. 결론 및 향후 연구 방향
5.1 연구 요약
본 연구는 풍력 터빈 고장 진단의 정확도와 신뢰성을 높이기 위해 ASMOTE-ENN 기법과 하이브리드 앙상블 모델을 제안하였다. 연구의 주요 성과는 다음과 같다.
1. 불균형 데이터 문제 해결
ASMOTE-ENN 기법을 활용하여 소수 클래스(고장 데이터)의 양과 품질을 개선하였다. 이 과정에서 데이터 증강과 노이즈 제거를 통해 균형 잡힌 고장 데이터를 확보하였다.
2. 하이브리드 앙상블 모델 도입
KNN, 의사결정 트리(DT), AdaBoost를 결합한 하이브리드 앙상블 모델을 활용하여 기존 단일 모델의 한계를 극복하고 고장 진단 성능을 극대화하였다.
5.2 연구의 시사점
본 연구는 풍력 터빈 유지보수 시스템의 혁신적 발전을 도모하며, 실질적인 운영 비용 절감과 유지보수 효율성 향상에 기여할 수 있다. 특히 다음과 같은 측면에서 의미를 갖는다.
1. 산업적 응용 가능성
제안된 모델은 풍력 터빈 외에도 다양한 산업군에서의 고장 예측과 진단에 적용될 수 있다. 예를 들어 제조업, 철도 시스템, 항공기 유지보수 등에서 비슷한 데이터 불균형 문제가 존재한다.
2. 실시간 데이터 통합
향후 디지털 트윈 기술과 통합될 경우, 실시간 상태 모니터링 및 고장 예측 시스템으로의 확장 가능성이 높다.
3. 기계 학습 모델의 고도화
하이브리드 앙상블 구조는 다양한 머신러닝 모델과 결합될 수 있어, 고장 진단의 정확도와 예측력을 더욱 향상시킬 수 있다.