기술분야

CAD와 AI의 현재, 그리고 미래
글 : 이진원 교수(강릉원주대학교) / jwlee@gwnu.ac.kr
1. 인공지능 정의와 역사
최근 몇 년간 가장 주목받고 있는 과학기술은 인공지능 (Artificial Intelligence, AI)이다. 인공지능은 빅데이터, 사물인터넷 등과 함께 4차 산업혁명의 핵심이다. 인공지능은 스마트폰의 보급과 하드웨어의 괄목할만한 성장으로 인해 빅데이터가 축적되기 시작하면서 데이터 기반의 연구가 본격적으로 시작되었다.
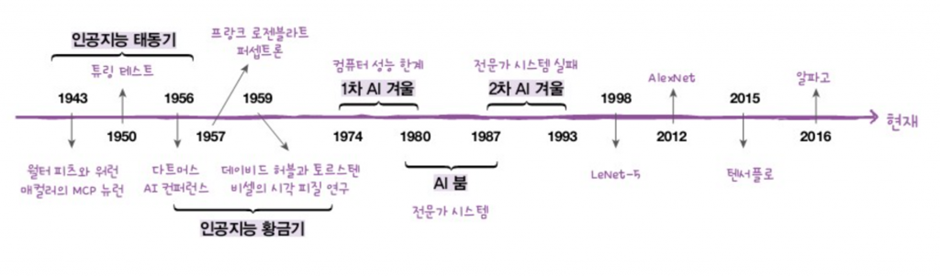
<그림 1> 인공지능의 역사 (출처: 혼자 공부하는 머신러닝+딥러닝, 한빛미디어)
1950년대에 처음 등장한 인공지능은 1차 황금기(1950년대, 인공신경망, 퍼셉트론), 1차 AI 겨울(컴퓨터 성능의 한계), 2차 황금기 (1980년대 전문가시스템), 2차 AI 겨울 (전문가시스템의 한계)를 거쳐 현재는 3차 황금기를 맞이하고 있다. 3차 황금기에 이르기까지 수많은 연구가 진행되었지만, 인공지능 연구의 변곡점은 세 가지 시점 (AlexNet, AlphaGo, ChatGPT)으로 표현할 수 있다. 대중들에게 AlphaGo와 ChatGPT가 큰 센세이션을 불러왔던 만큼, 연구자들에게 AlexNet은 많은 연구 패러다임을 바꾸는 계기가 되었다. 2012년에 AlexNet이 등장하기 전까지, ImageNet 대회에서 이미지 인식 연구는 사용자가 정의한 특징을 수학적인 알고리즘에 의해 분류하는 전통적인 방식으로 74%의 정확도를 보였다. 그러나 CNN (Convolutional Neural Networks) 기반의 AlexNet은 10%p이상의 정확도 향상을 이뤄내어 84%의 결과를 보였고, 이는 연구자들에게 큰 충격을 주었다. 이로써 본격적인 딥러닝의 시대가 열렸다.
그림 2에서 볼 수 있듯이, 인공지능은 가장 포괄적인 개념으로, ‘인공지능 ⊃ 머신러닝 ⊃ 딥러닝’의 관계가 성립된다. 인공지능은 컴퓨터가 인간의 사고를 모방하는 모든 기술을 의미하고, 머신러닝은 컴퓨터가 스스로 학습하는 것을 말한다. 딥러닝은 인간 뇌의 동작 방식에서 착안한 기술로서, 복잡한 여러 개의 레이어를 통해 학습하는 기술을 말한다.
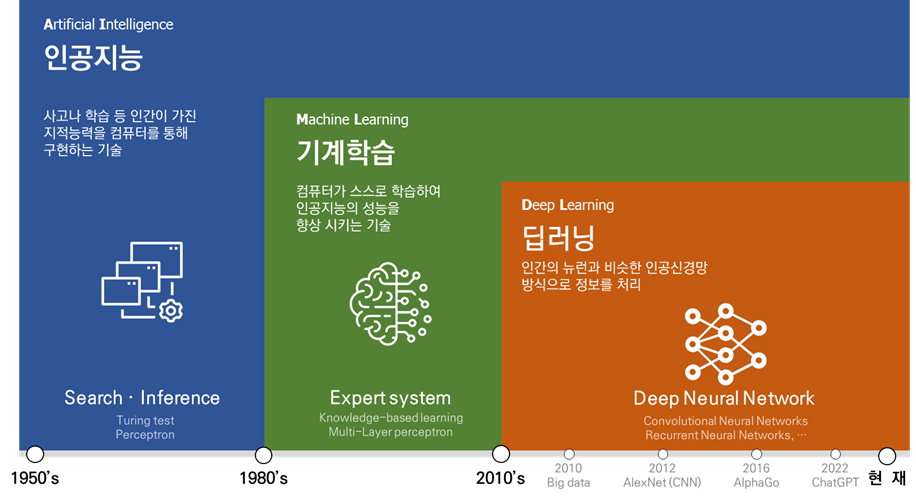
<그림 2> 인공지능의 정의
2. 머신러닝 알고리즘 종류
머신러닝은 데이터의 종류와 목적에 따라 지도학습 (Supervised
learning), 비지도학습 (Unsupervised learning), 강화학습 (Reinforcement learning)으로 나눌 수 있다. 지도학습은
레이블 (label, 혹은 정답)이 포함된 데이터를 활용하여
모델을 학습시킨다. 입력 (X data)이 주어지면, 그에 대한 결과 (Y data 혹은 label)를 전달하여 모델을 학습시킨다. 이 방식의 대표적인 문제
유형으로는 분류와 회귀가 있다. 비지도학습은 지도학습과 달리 정답이 없는 데이터만을 활용하여 데이터
간의 군집 혹은 패턴을 찾는 방법이다. 대표적인 비지도학습의 목적으로는 군집화와 차원 감소가 있다. 마지막으로, 강화학습은 지도학습과 비지도학습과는 조금 다른 개념으로, 주어진 환경 (Environment)에서 최대의 보상 (Reward)을 받기 위해 행동을 학습하는 것을 말한다.
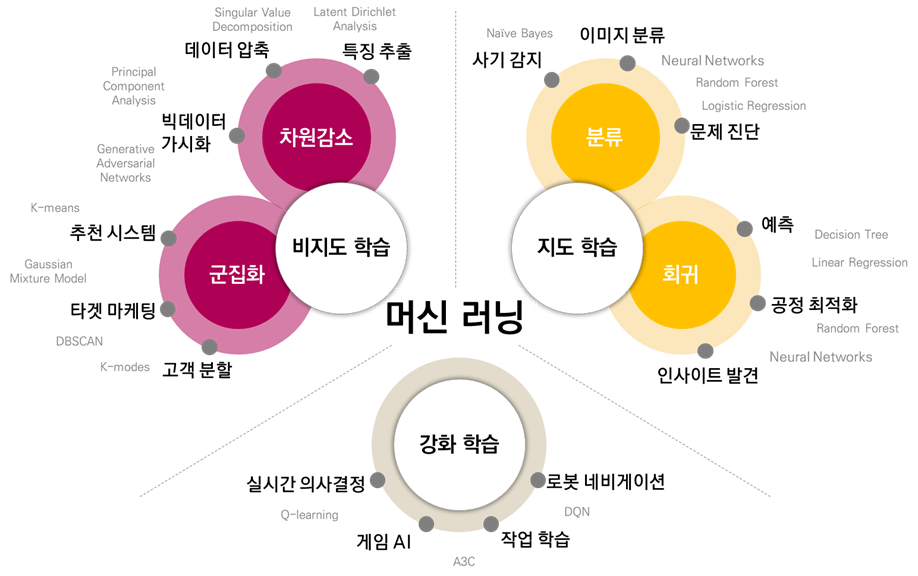
<그림 3> 머신러닝 알고리즘 종류
2012년 AlexNet의 등장 이후 인공지능의 주요 연구 흐름은 이미지 인식 (자율주행), 강화학습 (AlphaGo), 생성적 적대 신경망 (딥-페이크), 그리고 자연어 처리 (ChatGPT) 순서로 진행되고 있다. 대부분의 인공지능 기술은 일상생활과 밀접한 분야에 적용되며 발전해 왔음에 따라, 현재는 인공지능을 활용한 다양한 제품을 쉽게 접할 수 있게 되었다. 하지만 산업 및 엔지니어링 분야에서의 인공지능은 일상생활에 비해 아직 초기 단계에 머물러 있다. 그 이유는 인공지능 모델을 학습시키기 위해 충분한 데이터가 필요하지만, 산업 특성 상 데이터가 회사의 중요한 자산으로써 외부에 공개되지 않기 때문이다. 또한 이미지, 영상, 음성 데이터와 달리 엔지니어링 데이터는 굉장히 복잡하며, 인공지능의 입력 데이터로 전달하기 매우 어렵다. 그럼에도 불구하고, 최근에는 Autodesk와 NX가 제너러티브 디자인, 명령어 예측 등의 분야에서 인공지능을 적용하여 제품을 출시하고 있다. 또한, 고려대학교의 문두환 교수, 카이스트의 강남우 교수 등 국내 연구진들 역시 생산·설계 분야에서 인공지능을 적용하기 위한 다양한 연구를 수행 중이다.
3. CAD+AI 연구 소개
본 기고에서는 인공지능을 활용하여 CAD 데이터를 인식 및 분할할 수
있는 방법에 대해 소개한다. 특히, 중립 포맷 (STEP format)의 경계표현 모델 (B-Representation)에서
기계가공 특징형상 (ex. Slot, hole, chamfer, fillet, …)을 인식하는 연구를
수행했다. 딥러닝을 활용하여 기계가공 특징형상 인식한 연구는 3D
CNN과 GNN (Graph Neural Network)을 사용했다.
1) 3D CNN
일정한 영역 내의 이미지를 인식하는 2D 영상처리 딥러닝 모델에서 착안한
방법으로, 2D 이미지를 3D 복셀 (Voxel)로 확장했다. CAD 데이터를 일정한 크기 (64×64×64)의 복셀로
변환하여 딥러닝 네트워크에 전달했다. 딥러닝 네트워크에서는 2D Convolutional
operation을 확장한 3D Convolutional operation을 통해 학습이
이루어졌다. 딥러닝을 활용하여 CAD 데이터를 처리할 수
있는 방법을 제시한 연구였다. 하지만 2D 이미지에서 3D 복셀로 데이터를 확장하면서 연산 처리량은 기하급수적으로 늘었으며, CAD 데이터를
복셀로 변환하면서 데이터 손실이 발생하는 한계점이 있었다.
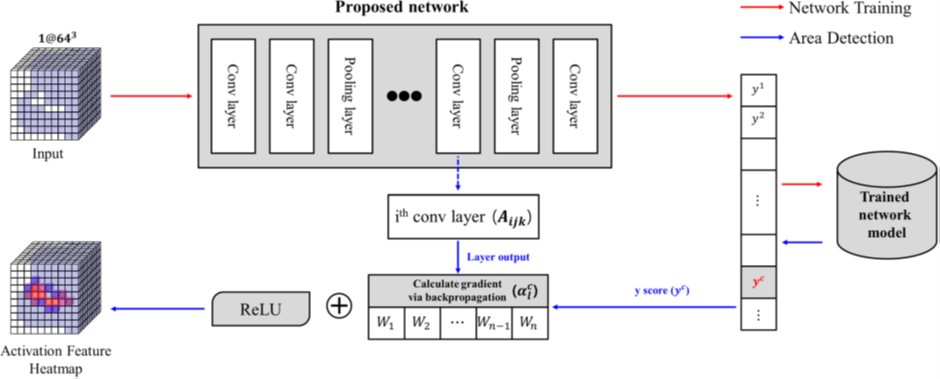
<그림 4> 3D CNN과 Grad-CAM을 활용하여 기계가공 특징형상 인식
2) Graph Neural Network
일정한 영역의 데이터를 입력데이터로 받아 학습하는 CNN의 특성때문에, 데이터의 크기가 불규칙적이고 매우 복잡한 CAD 데이터를 딥러닝 네트워크에 입력데이터로 전달하기 어렵다. 그렇기에 인공지능을 활용한 대부분의 연구는 raw CAD 데이터가 아닌 이미지나 복셀로 가공한 데이터를 사용하여 딥러닝 네트워크에 전달했다. 하지만 데이터를 가공하는 과정에서 데이터 손실이 발생하여 정확도가 떨어지는 문제가 있었다. 이를 해결하기 위해, graph neural networks에서 사용하는 데이터 구조 (graph data structure)가 경계표현 모델의 데이터 구조 방식과 유사하는 점에서 착안하여 연구를 진행했다.
4. 맺음말
인공지능은 수많은
연구자들의 노력과 투자 덕분에 일상생활에서 두각을 나타내고 있다. 그러나 아직까지 산업 및 엔지니어링
분야에서는 인공지능 연구를 위한 충분한 데이터를 확보하는 데 어려움이 있다. 현장에서 실용적으로 적용할
수 있는 인공지능을 개발하기 위해서는, 공개형 학습용 데이터셋 확보,
엔지니어링 분야의 인공지능 전문가 양성, 그리고 산학연간의 협력을 통한 현장 문제 해결에
대한 노력이 필요하다. 또한, 제조 디지털 트윈 연구회의
출범과 함께, 엔지니어링 분야에서 인공지능을 활용하기 위한 다양한 기본 데이터 수집과 연구가 더욱 활발하게
이루어지기를 바랍니다.