
1. Introduction
선박 항로가 점점 복잡해짐에 따라 자선의 잠재적 위험을 정확하게 예측하고 타선과 충돌 없이 안전 운항을 수행하는 해상 자율운항선박(Maritime Autonomous Surface Ship, MASS)용 자율운항 시스템에 대한 필요성이 커지고 있다. 자율 운항 시스템은 타선 등 해상 장애물의 위치, 속력, 진행 방향 등을 실시간으로 정확하게 파악해야 하며, 이를 기반으로 자선에 대한 각 타선의 상대적인 위험을 평가하고 적절한 시점에 충돌 회피를 수행해야 한다 [1].
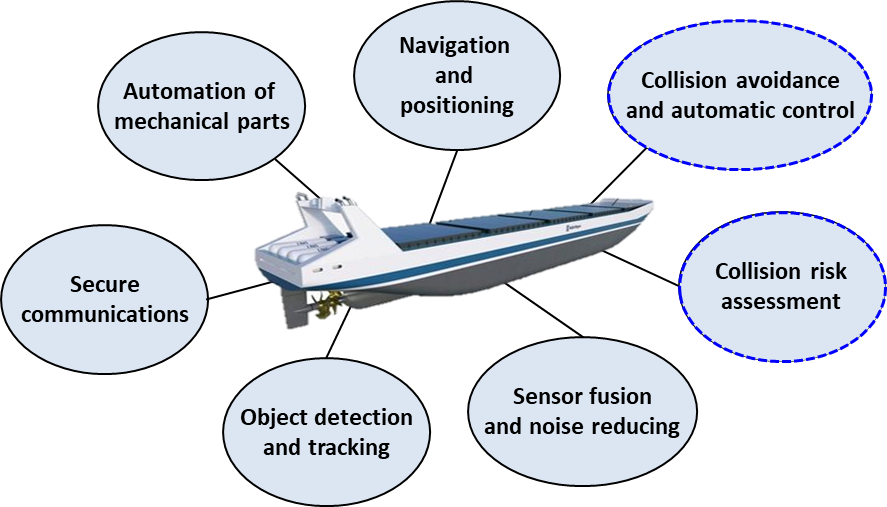
Figure 1.
Autonomous navigation system for MASS
2. Theoretical Backgrounds
본 연구에서 제안된 자율 운항 시스템은 AIS, RADAR, LIDAR 등
다양한 센서를 활용하여 타선의 위치, 속도, 방향을 실시간으로
파악하고, 이를 기반으로 충돌 위험을 평가하여 적절한 충돌 회피를 수행한다. 이때, 자율 운항 시스템은
1972년에 제정된 국제 해상충돌방지 협약(COLREGs) [2]을 준수해야 한다.
한편, 강화 학습(Reinforcement
Learning, RL)은 에이전트가 현재 상태에서 보상을 통해 계산된 가치 함수를 최대화하는 행동을 취하도록 학습하는 알고리즘이다 [3]. 마르코프 의사 결정 과정(Markov Decision Process,
MDP)에 기반을 두고 있으며, 행동 심리학에서 영감을 받은 머신 러닝의 한 분야로 수학적
모델링과 딥러닝(Deep Learning, DL)의 인공 신경망(Artificial
Neural Network, ANN)을 결합하여 의사 결정을 수행한다. 강화학습은 특정
환경 내에서 에이전트(Agent)가 현재 상태(State)를
바탕으로 보상(Reward)을 최대화하는 행동(Action)을
선택하여 최적의 정책(Policy)을 도출하는 방법을 탐색한다. 최근에는
딥러닝의 인공 신경망을 활용하는 강화 학습, 즉 심층 강화 학습
(Deep Reinforcement Learning, DRL)이 등장하여, 복잡한 문제에
대해 기존 RL보다 더 우수한 학습 성능을 제공하는 것으로 나타났다.
본 연구에서는, 자선 및 경로와 관련된 다양한 정보를 1차원 MLP(Multi-Layer Perceptron), 타선과 관련된 정보를 2차원 CNN(Convolutional Neural Network)으로 구성하여 다차원 상태를 정의한다. 또한, 자선의 타각(Rudder
Angle)과 프로펠러 회전 수(Propeller RPM)를 행동으로 선택한다. 마지막으로, 자선의 효율적인 운항을 위한 효율 보상(Rewards for path following)과 안전한 운항을 위한 안전 보상(Rewards for collision avoidance)을 결합하여 각 타임 스텝 마다 에이전트가 받는 보상을
정의한다. 이 때, 각 보상은 Figure 2와 같이 정의된다 [4].
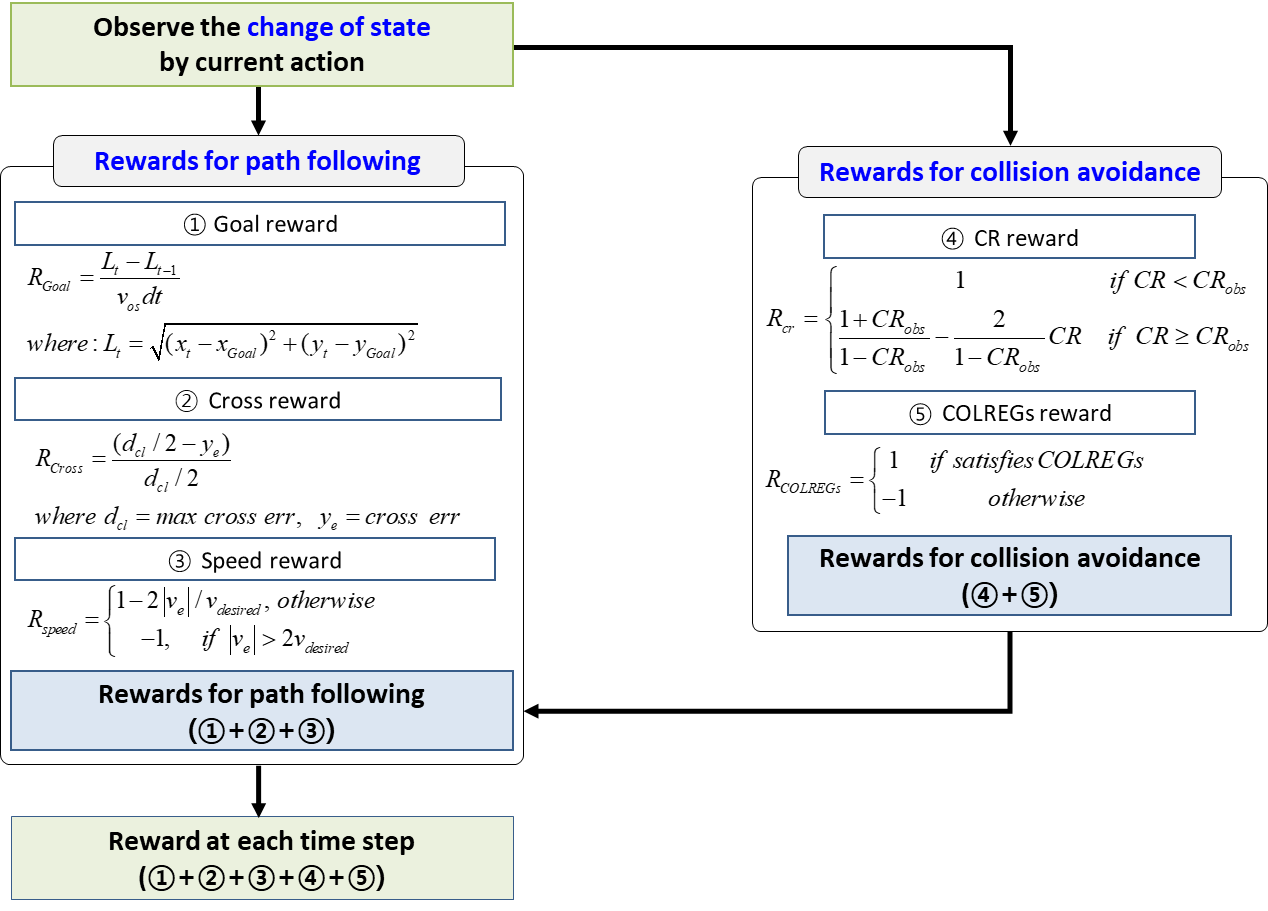
Figure 2. Procedure for calculating the
total reward
3. Applications
본 연구에서는 제안한 방법을 간단한 예제에 적용하여 그 효과를 검증했다. 이
때, 선박의 제원 및 운동 조종 성능이 공개되어 있는 초대형 원유운반선 KVLCC2 [5]의 모형 선박에 제안된 방법을 적용하였다. 본 연구에서는
제안된 심층 강화 학습 기반 충돌 회피 방법은 두 단계의 학습 과정을 거친다. 첫 번째 단계에서는 무작위성을
가진 체크포인트를 생성해 타선이 없을 때의 경로를 추종하는 학습을 하고, 두 번째 단계에서는 타선과의
충돌 회피 학습을 진행한다. Python 언어 기반의 PyTorch 프레임워크를
사용한 학습은 인텔 코어 i9-12900K CPU, 32GB RAM, Geforce GTX 1080Ti GPU를
장착한 PC에서 수행되었다. 시간당 약 100 epoch의 학습 속도를 보였으며, 첫 번째 단계는 약 1,000 epoch, 두 번째 단계는 약 5,000 epoch 후에
학습이 완료되었다. 각 단계 별 시간당 총 보상은 Figure 3과 같다.
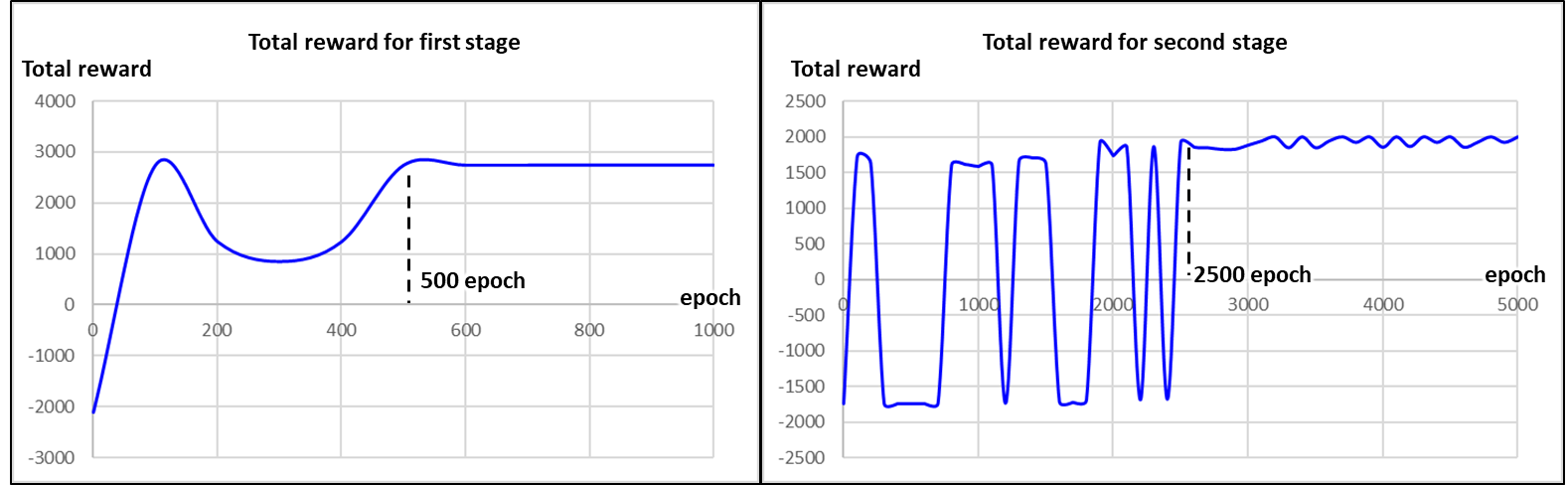
Figure 3. The total reward for each stage
본
연구에서는 여러 대의 타선이 자선 방향을 향해 운항할 때 DRL 기반 충돌 회피 방법의 예제를 수행했다. OS의 초기 위치는 (0,0)이고 최종 목적지는 (0, 1000 m)이다. 자선 및 각 타선의 초기 위치는 Figure 4와 같다. 또한, 본
연구에서는 위험한 상황에서도 제안된 방법이 모든 타선들을 회피하는 안전한 경로를 생성하는지 확인하기 위하여, 모든
타선들이 경로를 유지할 때와 각 타선의 움직임에 무작위성이 있을 때 충돌 회피 결과를 확인하였다.
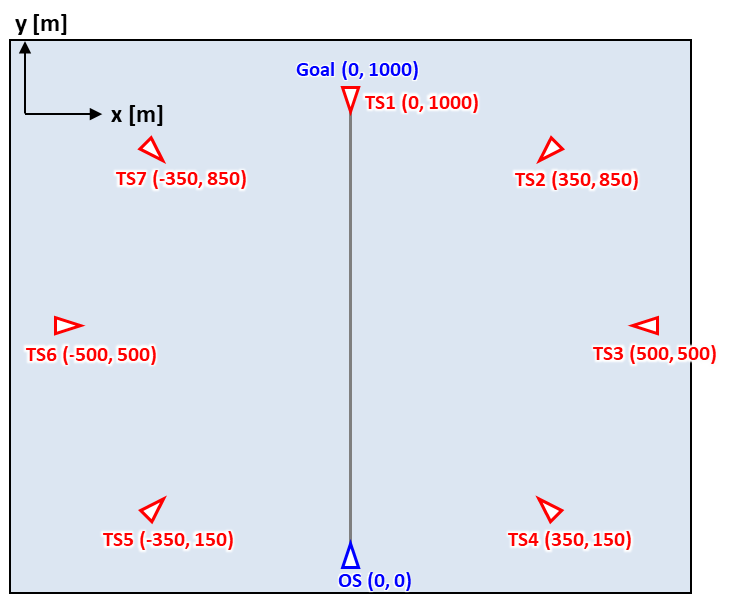
Figure 4. All TSs used in the example for
the collision avoidance method
먼저, 모든 타선이 경로를 유지할 때 자선의 경로는 Figure 5와 같다.
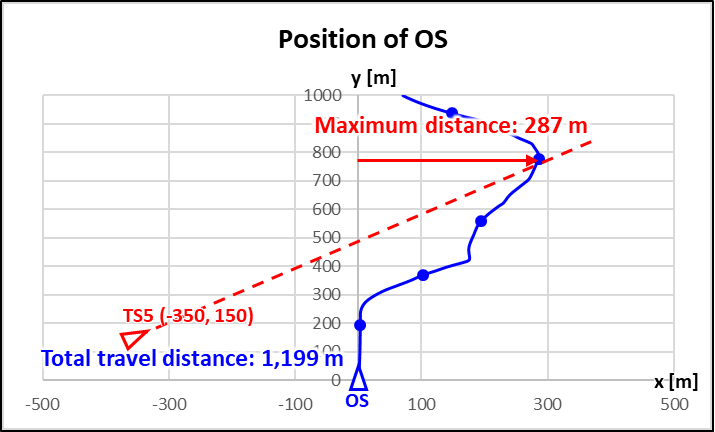
Figure 5. Position of the OS when all TSs
maintan their own path
다음으로, 각 타선의 움직임에 무작위성이 있을 때 자선 및 타선들의
경로는 Figure 6과 같다.
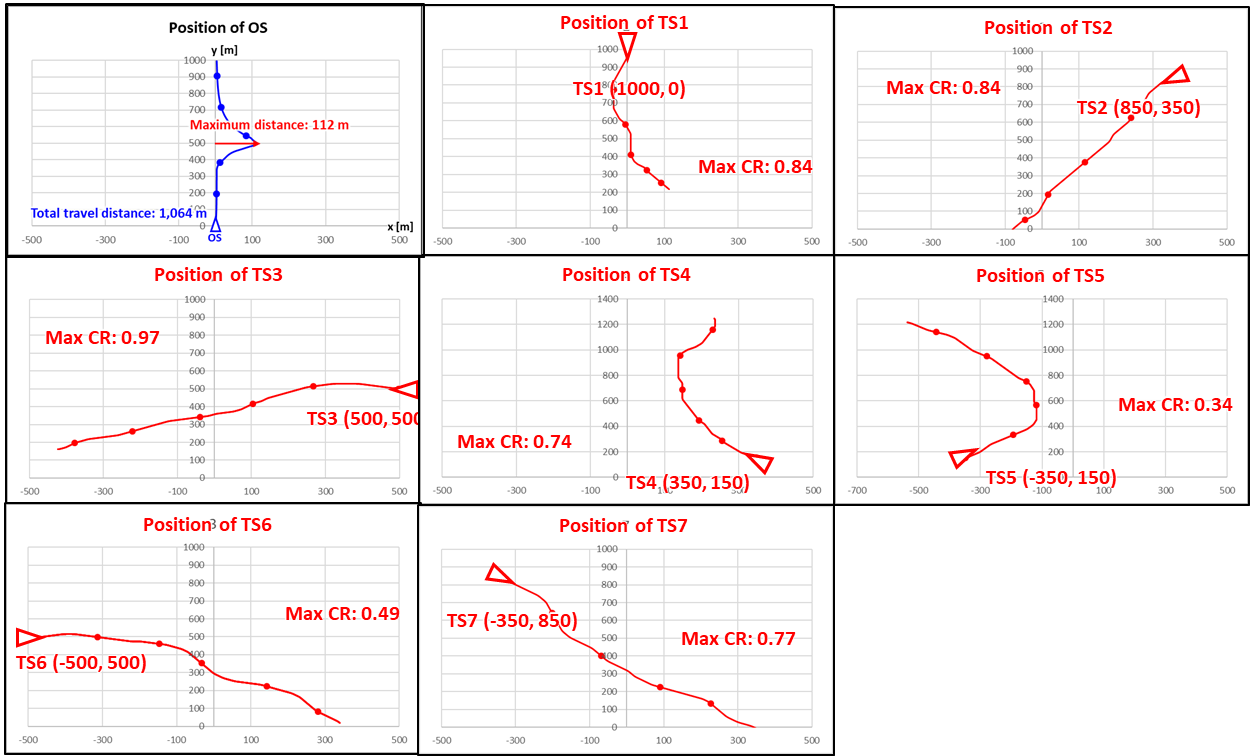
Figure 6. Path of the OS and TSs when all
TSs change the movements randomly
모든 타선들이 자선 방향으로 직선으로 다가올 때와 각 타선들의 움직임에 무작위성이 있을 때 모두, 제안된 심층 강화 학습 기반 충돌 회피 방법을 적용하여 타선들과 충돌하지 않는 안전한 경로를 생성하는 것을
확인하였다.
4. Conclusions and Future Works
본 연구에서는 각 대상 선박과 자기 선박의 상대적 위험도를 평가하고 적절한 시점에 충돌 회피를 수행할 수 있는
해상 자율운항선박의 자율운항 시스템을 제안한다. 자율운항 시스템의 경우, 다수의 타선을 동시에 고려하여 자선의 경로와 속력을 도출하는 심층 강화 학습 기반 충돌 회피 방법을 제안한다. 제안하는 방법은 자선 주변의 여러 타선을 동시에 인식하고 모든 타선을 기준으로 충돌 회피를 수행한다. 또한, 자선의 타각와 프로펠러 회전 수를 함께 제어하여 가장 효율적인
경로와 속력을 도출한다. 그 결과, 제안한 자율운항 시스템은
타선들이 밀집해 있고 매우 위험한 환경에서도 안전한 운항이 가능함을 확인했다.
5. References
[1] D. H. Chun, M. Il Roh, H. W. Lee, J. Ha, and D. Yu, “Deep reinforcement learning-based collision avoidance for an autonomous ship,” Ocean Engineering, vol. 234, p. 109216, Aug. 2021, doi: 10.1016/J.OCEANENG.2021.109216.
[2] Convention on the International Regulations for Preventing Collisions at Sea, 1972 (COLREGs)
[3] L. Zhao and M. Il Roh, “COLREGs-compliant multiship collision avoidance based on deep reinforcement learning,” Ocean Engineering, vol. 191, p. 106436, Nov. 2019, doi: 10.1016/J.OCEANENG.2019.106436.
[4] D. H. Chun, M. Il Roh, H. W. Lee, and D. Yu, “Method for collision avoidance based on deep reinforcement learning with path-speed control for an autonomous ship,” International Journal of Naval Architecture and Ocean Engineering, vol. 16, p. 100579, 2024, https://doi.org/10.1016/j.ijnaoe.2023.100579.
[5]
S. Y. Kim and Y. G. Kim, “Prediction of Maneuvering Performance for
KVLCC1 & KVLCC2 Based on PMM Data,” Proceeding of SIMMAN 2008.
대표이사: 유병현 / 사업자등록번호: 220-82-60063
Copyright© 2023. Society for Computational Design and Engineering. All rights